

जब आप इन्टरनेट पर सर्च इंजन में अपनी कोई जानकारी सर्च करते है और वो जानकारी कुछ ही पल में आपके सामने आ जाती है तो यह कैसे आती है यह जानकारी को कौन आपके सामने लाता है यह वेब Crawlier/Spider/Bots क्या है यह कैसे काम करते है ?
जब आप इन्टरनेट पर किसी जानकारी को सर्च करते हो जैसे -“कंप्यूटर क्या है ” तो गूगल आपको आपके Question का Answer खुद से नहीं देता है वो आपके Question का Answer देने के लिए एक प्रोग्राम की मदद लेता है जिन्हें वेब Crawlier/Spider/Bots कहते है
वेब Crawlier/Spider आपके Question से सम्बंधित सभी वेबसाइट के लिंक ,कंटेंट , इमेज को चेक या Scan करता है और देखता है कि किन-किन वेबसाइट के कंटेंट,लिंक,इमेज,टाइटल आपके Question से Match हो रहा है और फिर आपके सामने आपके Question से सम्बंधित वेबसाइट की List आपके डिस्प्ले पर दिखा देता है-
Crawlier/Spider गूगल Index में आपके Question से सम्बंधित उसी वेबसाइट को दिखता है जो गूगल के Algorithm के अधीन इन्टरनेट पर कार्य करती है गूगल के algorithm को आप गूगल के अनुशासन नियम भी बोल सकते हो.
Crawlier/Spider/Bots इन्टरनेट पर कैसे कार्य करते है?
जब आप इन्टरनेट पर गूगल सर्च इंजन में अपने Question से सम्बंधित Keyword/Phrase के रूप में सर्च करते हो
For Example-“कंप्यूटर क्या है “
तो गूगल का सर्च इंजन आपके Question का Answer देने के लिए Crawlier/Spider/Bots प्रोग्राम की मदद लेगा Crawlier/Spider इन्टरनेट पर सभी वेबसाइट के Source Code को पढता है यानि Crawling करते है जैसे – वेबसाइट में आपके Question सम्बंधित टाइटल , कंटेंट , इमेज , लिंक को चेक करता है फिर गूगल के Indexing Page में Index करा देता है जिससे आपको आपके Question का Answer मिल जाता है.
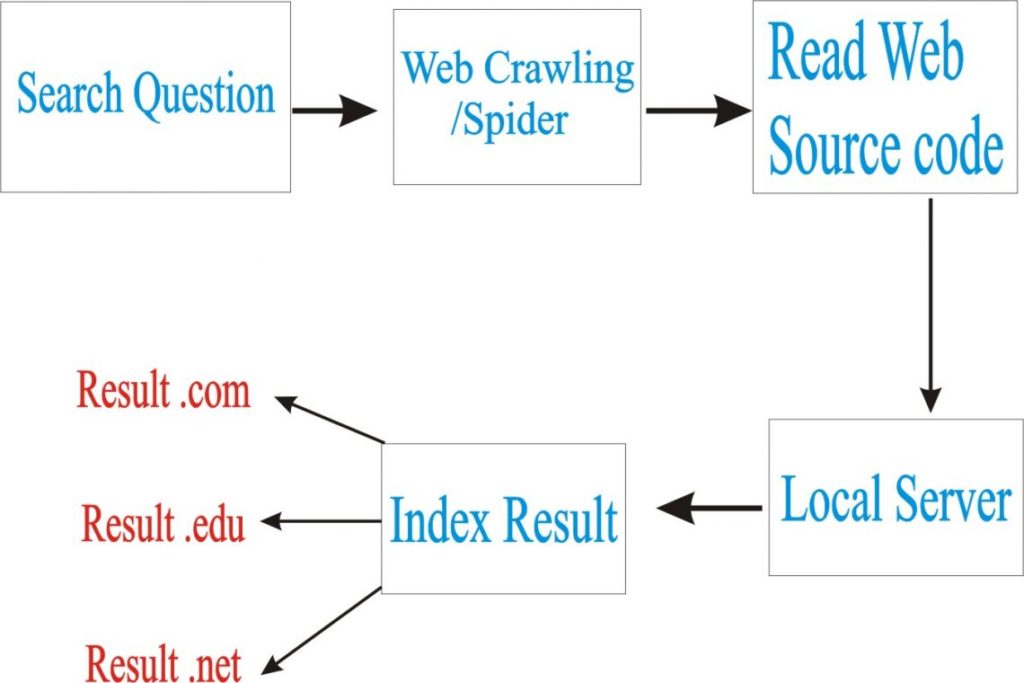
ध्यान दें- इन्टरनेट पर गूगल उन्हीं वेबसाइट को गूगल पर Index करता है जिस वेबसाइट का लिंक गूगल के Web Master Tool/Search Console में Submit हो यानि आपकी वेबसाइट को गूगल पर रैंक या Indexing करने के लिए आपको अपनी वेबसाइट के लिंक को Web Master Tool/Search Console में Submit करना होता है यह एक फ्री सर्विस है .